Visualisasi Metrik Log Access Nginx menggunakan Loki dan Grafana
Tulisan ini merupakan lanjutan dari tulisan sebelumnya yang ada di sini. Sebelum mengikuti instruksi di bawah, pastikan Promtail sudah terinstal dan pengaturannya sudah disesuaikan. Pada tulisan ini, visualisasi log access servis Nginx yang akan ditampilkan adalah hasil pengolahannya dalam bentuk metrik. Metrik yang dimaksud di sini adalah informasi log yang dapat diukur. Berikut beberapa visualisasi metrik log access servis Nginx yang akan dibuat.
Total Requests
Selain untuk mengetahui berapa jumlah requests yang ada di suatu domain, contoh example.id, visualisasi ini juga bisa digunakan untuk mengetahui berapa total log yang terdapat dalam suatu file/domain. Berikut langkah untuk membuat visualisasi ini:
Pada bagian navigasi menu di sebelah kiri aplikasi Grafana, pilih Dashboards.
Pilih dan klik ke dashboard yang sudah dibuat sebelumnya.
Klik Add visualization.
Pilih Stat sebagai tipe visualisasi yang akan digunakan.
Pada Title di bagian Panel options di sebelah kanan aplikasi Grafana, isi dengan Total Request Logs. Silahkan judulnya disesuaikan dengan Anda.
Pada Unit di bagian Standard options pilih short.
Standar unit short membuat ukuran jadi dipersingkat. Misal 1000 ditulis jadi 1k, 1000000 ditulis jadi 1M.
Pada bagian Thresholds di sebelah kanan aplikasi Grafana, hapus nilai beserta warna threshold default yang bernilai 80. Pada nilai base, silakan tentukan warna yang digunakan untuk menampilkan nilai metrik dari visualisasinya.
Pada bagian Data source di bagian bawah tab Queries, pastikan loki yang terpilih.
Langkah dari 1 sampai 8 sama untuk membuat visualisasi metrik-metrik berikutnya. Yang membedakan langkahnya hanya penentuan Title, Unit, dan kueri di bagian Code.
Pilih tab Code, lalu masukkan kueri berikut.
1
sum(count_over_time({filename="$filename"} [$__auto]))
Keterangan:
{filename="$filename"}merupakan selector log. Loki akan mencari semua log yang memiliki label filename yang nilainya sesuai dengan variabel $filename.[$__auto]merupakan rentang waktu yang nilainya otomatis akan disesuaikan saat user menentukannya.count_over_time(...)merupakan fungsi untuk menghitung baris log yang muncul pada periode atau rentang waktu tertentu.summerupakan fungsi untuk menjumlahkan semua hasil dari kriteria kueri yang ada menjadi satu angka total.
Jalankan Run query di bagian tab Queries.
Silakan atur ukuran dan posisi dengan cara drag and drop visualisasinya.
Total Requests Status Code (2/3/4/5xx)
Total requests juga bisa dikelompokkan berdasarkan status kode HTTP. Umumnya status kode dapat dikelompokkan berdasarkan inisial angkanya.Berikut penjelasan singkat terkait pengelompokkan status kode HTTP berdasarkan inisial angkanya:
2xx: Request berhasil diproses dan diterima.3xx: Client memerlukan tindakan lanjut untuk menyelesaikan sebuah request. Contohnya resource (URL) dari request dipindahkan atau dialihkan (redirected) ke resource lain4xx: Terjadi eror atau kesalahan dari sisi client.5xx: Terjadi eror atau kesalahan dari sisi server.
Contohnya kita ingin membuat visualisasi untuk menampilkan jumlah requests status kode 2xx, maka kuerinya mirip seperti kueri sebelumnya, namun dengan tambahan penggunaan operasi regular expression di LogQL. Kueri akhirnya akan menjadi seperti ini:
1
sum(count_over_time({filename="$filename", status=~"2[0-9]{2}"}[$__auto]))
2[0-9]{2} artinya bisa bernilai 200-299:
- Angka pertama 2, status kode dimulai dari 2xx.
[0-9]{2}: Dua angka berikutnya bisa apa saja, 0-9.
Kueri untuk total requests status kode 3xx:
1
sum(count_over_time({filename="$filename", status=~"3[0-9]{2}"}[$__auto]))
Kueri untuk total requests status kode 4xx:
1
sum(count_over_time({filename="$filename", status=~"4[0-9]{2}"}[$__auto]))
Kueri untuk total requests status kode 5xx:
1
sum(count_over_time({filename="$filename", status=~"5[0-9]{2}"}[$__auto]))
Error Rate (5xx)
Metrik error rate (5xx) merupakan rasio antara total requests dengan status kode 5xx dan total seluruh requests yang ada. Metrik Error rate (5xx) merupakan salah satu dari four golden signals yang sangat penting dalam monitoring. Four golden signals terdiri dari latency, error rate, traffic/throughput, dan saturation.
Kenapa informasi status kode eror 5xx lebih penting dari 4xx?
Status kode 5xx menunjukkan adanya masalah internal dari sisi sistem atau infrastruktur suatu sistem atau aplikasi yang Anda kelola. Masalah ini menimbulkan dampak bahwa server gagal memproses requests dikarenakan downtime pada sistem sehingga memerlukan prioritas yang sangat tinggi untuk diselesaikan. Sedangkan status kode 4xx lebih menunjukkan kesalahan dari sisi penggunaan aplikasi oleh user. Status kode 5xx terkait kebutuhan non-fungsional dan 4xx terkait kebutuhan fungsional suatu aplikasi.
Berikut kode kueri untuk metrik ini:
1
(sum(count_over_time({filename="$filename", status=~"5[0-9]{2}"} [$__auto])) * 100) / sum(count_over_time({filename="$filename"} |= `` [$__auto]))
Latencies (95th & 99th Percentile)
Latency merupakan waktu yang dibutuhkan untuk memproses sebuah requests dari client hingga mendapatkan respons dari server. Semakin kecil nilai latency maka semakin baik dan efisien suatu sistem atau aplikasi bekerja. Metrik latencies dapat menggunakan label request_time pada log access di servis Nginx. Standar industri sekarang umumnya menggunakan persentil ke-95 (P95) untuk mengukur latencies. Namun, tak sedikit pula yang menggunakan persentil ke-99 (P99) juga. Penggunaan P99 dapat sangat berguna untuk sistem kritikal yang meimiliki SLA (Service Level Agreement) yang sangat ketat, contohnya sistem perbankan atau game online.
Alasan utama kenapa P95 lebih sering digunakan ketimbang rata-rata adalah karena P95 lebih representatif dan juga mengabaikan nilai outliers yang sangat memengaruhi hasil rata-rata. P95 mengukur latencies pada 95% requests tercepat dan mengabaikan 5% requests yang paling lambat. Hal ini memberikan gambaran yang lebih jelas tentang performa sistem normal tanpa terpengaruh oleh kejadian langka yang mungkin hanya terjadi sesekali.
Penting agar latencies hanya mengambil waktu dari requests yang sukses (2xx dan 3xx) saja. Hal ini dikarenakan requests yang eror dapat mengacaukan hasil nilai latency. Contohnya, waktu respons eror cepat, tapi sistemnya bermasalah. Fokus utama latency adalah mengukur performa normal (requests sukses) dari suatu sistem, tidak termasuk saat eror muncul.
Berikut kode kueri untuk metrik 95th percentile latencies:
1
quantile_over_time(0.95, {filename="$filename", status=~"[2-3][0-9]{2}"} | unwrap request_time [$__auto])
Keterangan:
status=~"[2-3][0-9]{2}berarti status kode dimulai dari angka 2 atau 3.unwrap request_timeberfungsi untuk mengubah tipe nilai dari label request_time menjadi angka untuk diolah ke prhitungan.quantile_over_time(0.95, ... )menghitung P95 dari semua nilai request_time yang dikumpulkan dalam periode atau rentang waktu tertentu.
Unit yang digunakan adalah seconds (s).
Kueri untuk metrik 99th percentile latencies
1
quantile_over_time(0.99, {filename="$filename", status=~"[2-3][0-9]{2}"} | unwrap request_time [$__auto])
Throughput (Requests/Second)
Throughput bertujuan untuk mengukur banyak requests yang diterima oleh sistem Anda. Metrik ini juga dapat digunakan untuk mengetahui tren pertumbuhan user dari suatu aplikasi serta mencatat lonjakan traffic requests yang dapat menyebabkan masalah performa.
Pada throughput, perhitungannya tidak membedakan requests berdasarkan status kode manapun, karena semua requests berkontribusi terhadap penggunaan resource dari suatu sistem.
Kueri untuk metrik throughput (requests/second):
1
sum(rate({filename="$filename"}[$__auto]))
Keterangan:
rate(...)merupakan fungsi untuk menghitung jumlah log per detik berdasarkan periode atau rentang waktu tertentu.
Unit yang digunakan adalah requests/sec (rps).
Jika ingin menggunakan satuan requests/minute, Unit yang digunakan adalah requests/min (rpm).
Berikut merupakan contoh penampakan akhir dari semua visualisasi terkait log access servis Nginx yang sudah dibuat.
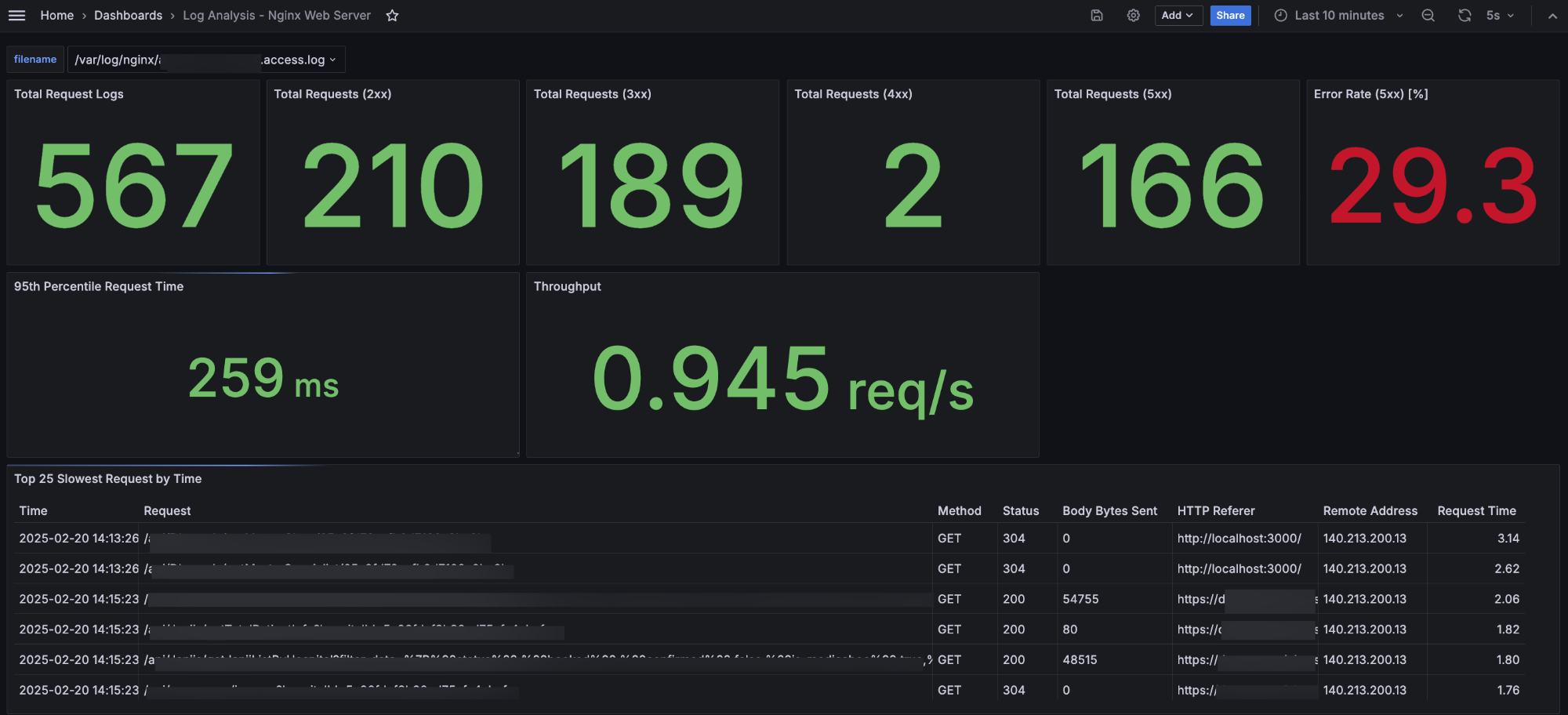 Visualisasi Log Access Servis Nginx
Visualisasi Log Access Servis Nginx